
Introduction
Exploring and understanding efficient image representations is a long-standing challenge in computer vision. While deep learning has achieved remarkable progress across image understanding tasks, its internal representations are often opaque, making it difficult to interpret how visual information is processed. In contrast, classical visual descriptors (e.g. edge, colour, and intensity distribution) have long been fundamental to image analysis and remain intuitively understandable to humans. Motivated by this gap, we ask a simple question: can modern learning benefit from these timeless cues? In this paper we answer it with VisualSplit, a framework that explicitly decomposes images into decoupled classical descriptors, treating each as an independent but complementary component of visual knowledge. Through a reconstruction-driven pretraining scheme, VisualSplit learns to capture the essence of each visual descriptor while preserving their interpretability. By explicitly decomposing visual attributes, our method inherently facilitates effective attribute control in various advanced visual tasks, including image generation and editing, extending beyond conventional classification and segmentation, suggesting the effectiveness of this new learning approach towards visual understanding.
Key Contributions
- We revisit classical visual descriptors and introduce a new learning paradigm -- VisualSplit, to explore the representation learning capacity using such simple descriptors.
- Aligning closely with human perceptual understanding, the proposed approach highlights the potential of the overlooked classical while effective visual descriptors.
- Extensive experimental analysis on low-level and high-level vision tasks, covering various applications, validates the effectiveness of our VisualSplit learning approach. It shows that precise, independent, and intuitive manipulation of image attributes (such as geometry, colour, and illumination) can be achieved.
Method at a Glance

Inputs
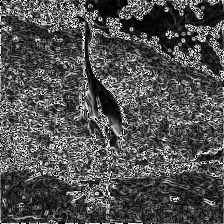
Edges: structural contours (e.g., Sobel/Canny).
Colour Segmentation: region-level appearance with a small number of colour clusters (choose K).
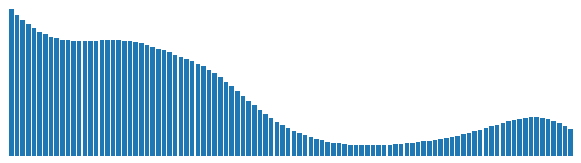
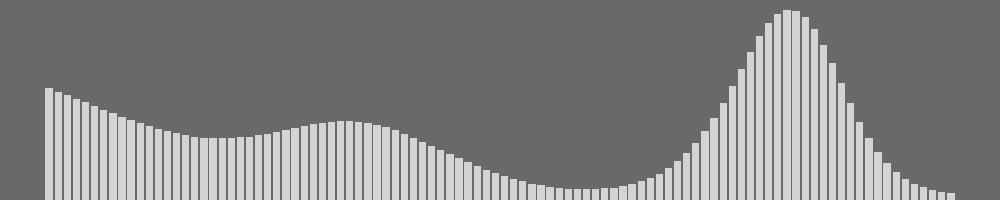
Grayscale Histogram: global luminance statistics (e.g., 100 bins).
Backbone
A ViT encoder consumes local tokens (edges/segments) and a global conditioning vector (histogram). Cross-attention and AdaLN-style conditioning inject descriptor information into learnable image tokens.
Objective
The decoder reconstructs the RGB image. The encoder is thereby trained to bind structure, region colour, and luminance in a controllable yet compact representation—without text prompts or masking schedules.
Descriptor-to-Image
VisualSplit treats an image as a composition of three classical, human-interpretable cues—an edge map for geometry, a segmented colour map for region-wise chroma, and a grey-level histogram for global illumination—and learns to reconstruct the scene using only these decoupled descriptors rather than raw RGB. This mask-free pre-training encourages the encoder to capture globally and locally meaningful structure from “informative absences,” yielding explicit, disentangled representations.
The example here illustrates the idea: starting from the original photo (left), we extract the three descriptors (second column); a human artist, seeing only these cues, can already infer and sketch the scene (third); our model then recovers a faithful image from exactly the same inputs (right), demonstrating that the combined descriptors are sufficient for robust reconstruction. Because each descriptor governs a different attribute—edges ≈ shape, colour segments ≈ region colours, histogram ≈ brightness—the representation is naturally interpretable and controllable, enabling independent edits of geometry, colour, or illumination in downstream generation and editing tasks.

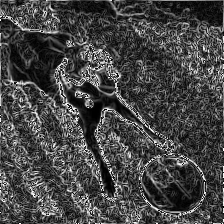



We thank Jie Dong for the illustration; used with permission.
Independent Controls
VisualSplit separates geometry, region colour, and global illumination into distinct, human-interpretable inputs—edges, segmented colours, and a grey-level histogram—and trains the encoder to reconstruct images by integrating these cues. Because edges/colours are treated as local patch inputs while the histogram conditions the model globally (via cross-attention and AdaLN-Zero), changing one descriptor steers only its corresponding attribute of the output. Empirically, varying the histogram alters brightness without affecting shape or region colours, and swapping the colour map changes chroma while preserving layout and lighting—demonstrating descriptor-level independence for controllable generation and editing.
Illumination (Histogram)
The grey-level histogram summarizes scene brightness and contrast at a global level. Feeding a different histogram (e.g., from low/normal/high-exposure captures) shifts the reconstructed image’s illumination accordingly, while edges and colour segmentation are held fixed—so geometry and regional colour remain stable. This provides a clean “exposure dial” for editing and restoration without touching other attributes.


Colour (Segmentation)
The segmented colour map assigns coherent regions to colour clusters, letting you recolour specific parts of an image independently of shape or lighting. Replacing only the colour map (e.g., from a re-balanced version of the same photo) changes regional chroma while edges and the global histogram stay intact; editing the map directly enables prompt-free, region-precise recolouring that respects boundaries.


Applications
VisualSplit learns decoupled, human-readable controls—edges (geometry), segmented colours (regional chroma), and a grey-level histogram (global illumination)—and plugs them into modern image generators to steer both global layout and local details. In practice, we pair our global representation with the text embedding (IP-Adapter–style) and inject local representations via ControlNet into Stable Diffusion 1.5, enabling faithful reconstruction and precise attribute control from descriptors alone.
A. Visual Restoration with Diffusion Models
Using only edge, colour-map, and histogram inputs, our guidance restores images with substantially higher fidelity than ControlNet, T2I-Adapter, and ControlNet++. This shows that descriptor-structured conditions recover both global appearance and fine structure more reliably than raw controls.

Other Models




B. Descriptor-Guided Editing (No Retraining)
Because each descriptor governs a different attribute, editing is as simple as modifying that input and re-running the generator—no model fine-tuning or prompts required. Swapping the colour map alters regional colours while preserving shape and lighting; changing only the histogram shifts exposure/contrast without touching geometry or chroma. Qualitative and user-study results confirm higher naturalness, accuracy, and consistency than prompt-based baselines.
1. Gray-Level Histogram Editing
We edit illumination by adjusting the grey-level histogram or applying histogram equalisation, then condition the generator with the updated histogram while keeping edges/colours fixed.





2. Colour Map Editing
To recolour specific regions, we modify only the segmented colour map (e.g., re-balanced hues or hand-edited segments). The diffusion model recolours those regions, respecting edge boundaries and the original illumination, and requires no text prompts—unlike baselines that need prompt engineering.


Other Models




Poster
BibTeX
@inproceedings{Qu2025VisualSplit,
title = {Exploring Image Representation with Decoupled Classical Visual Descriptors},
author = {Qu, Chenyuan and Chen, Hao and Jiao, Jianbo},
booktitle = {British Machine Vision Conference (BMVC)},
year = {2025}
}